Machine Learning: How to get started
Feb. 11, 2021
Read time: 4 minutes and 57 seconds.
tags:What is machine learning?
Machine learning sounds opaque, but it’s more of a general term for statistical learning algorithms that continuously improve through experience. How do things improve in general? Through training! So, let’s say something happens that can be recorded or observed (in a table or dataset) such as a transaction or speed of a vehicle, this information can be used as a form of training data. From your training data, you need to establish what question you might try to answer with a metric of success (commonly known as your predictor). When more data (read experience) becomes available, the algorithm can fine tune it’s results according to what is next. That’s it.

Have an interview with Google? You’re basically ready to conquer AT LEAST that question.
All kidding aside, this is the general starting point in machine learning that can help you understand what this term means and how it might be used. Machine learning can be dense subject matter when going into the mechanics and best practices so if it’s an area that interests you, become familiar with information on these topics.
Dependencies
Now that we have general prerequisites out of the way, we can now get started with what you actually need to do this. So what is that exactly? Well:
- Computer - In this tutorial, we’ll use a Windos PC. You might be able to run scripts on your iPhone or Android including some open source options. Dependencies usually vary on mobile so I don’t recommend it
- Anaconda - A flexible platform for quickly getting started on python
- Courage - Some of this might seem tricky at first if you’ve never done it before. Just keep at and don’t be afraid to seek out answers
- Patience - This is for those eager to get started with their own algorithms and applications. It will take time and typically it’s a matter of defining a problem well for the solution. If you need a break, check out these gifs or go for a walk
From these dependencies, you’ll really just need to install Anaconda according to your machine needs. In case you need more information for this step, here are the official docs, instructions on Windows, or Mac OS
Creating an environment
You should now have Anaconda and can load the navigator screen from your programs. Once you’re in navigator, you will select the Environment menu on the left hand-side and click Create to establish your Ananconda environment. In mine, i’ve called the environment ml-tutorial. You should see something like this:
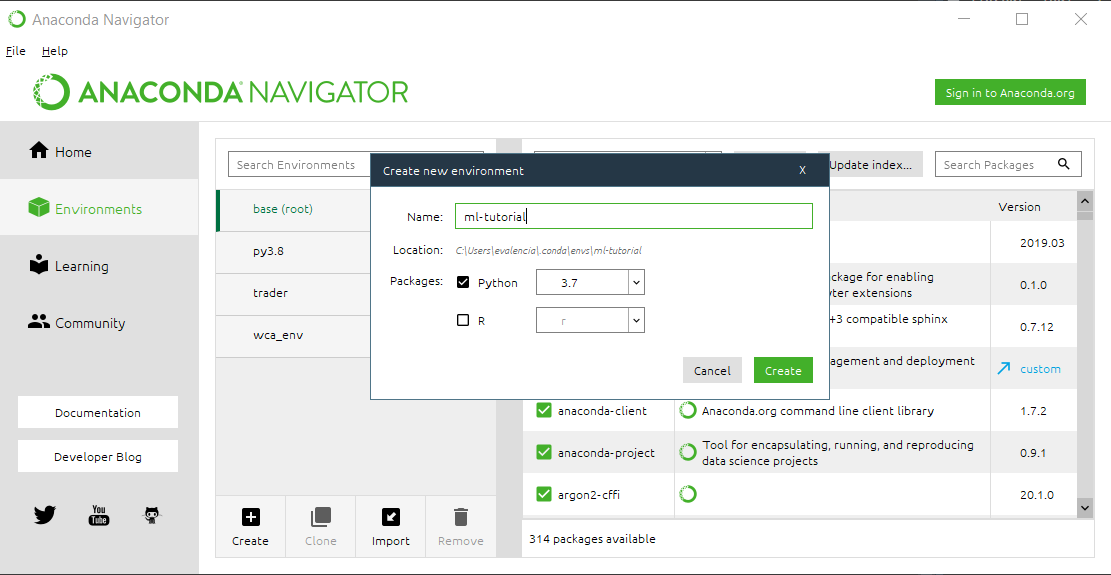
An environment using Anaconda is a way of creating a set of scripts or modules that won’t interfere with other modules. Since the world of python is so diverse, some packages exhibit conflicts at a lower programming level that isn’t made clear to the user and can drive you mad. Avoid the madness by creating an environment and installing what you need.
Install packages
Assuming you’ve never touched python before, this step can simply be done in the user interface of Anaconda. If you’ve used python in the past and prefer it, you can also install by command line with anaconda as well. See the docs for more about conda command line interface
For this tutorial, you’ll need to install two packages for the ml-tutorial environment we created previously:
- notebook - A visual notebook where you can test out your code added as an application icon
- scikit-learn - A rich machine learning library with tons of working examples
- matplotlib - A way to show the pretty graphs and plots
This is what your installation prompt might look like:
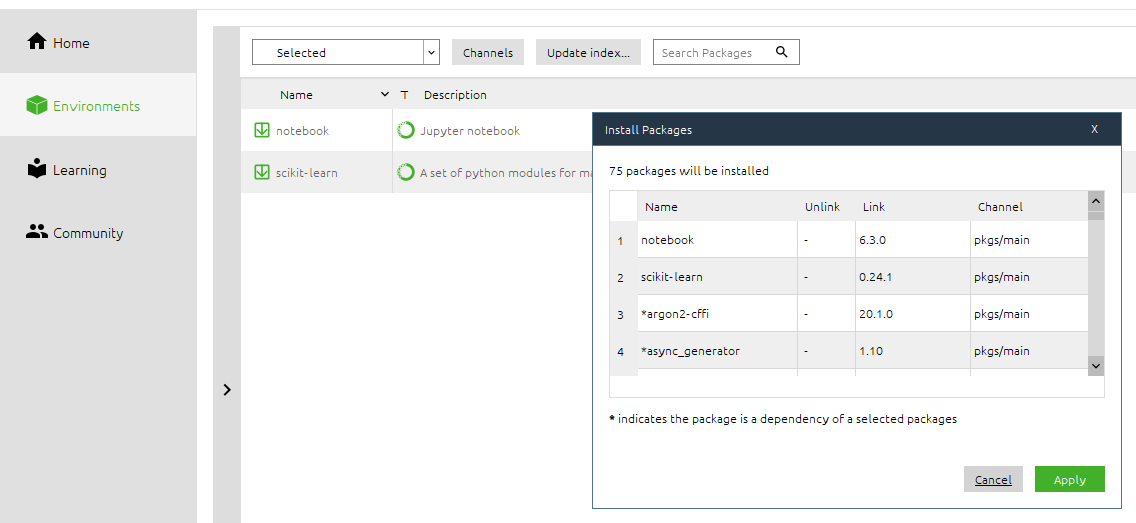
This stage might take a few minutes to complete as it looks for dependencies, but you should later see the packages in the list on the right hand side of the navigator. For more detailed instructions, see the anaconda package manager guide with the Anaconda Navigator.
Notebook
So you created an environment and installed the dependencies! Great work, we are almost at the finish line! 🏁
Now that you’ve created your ml-tutorial environment, using the search in Windows or spotlight in Mac OS you should see the notebook application for the environment. Here’s what it looks like on windows:
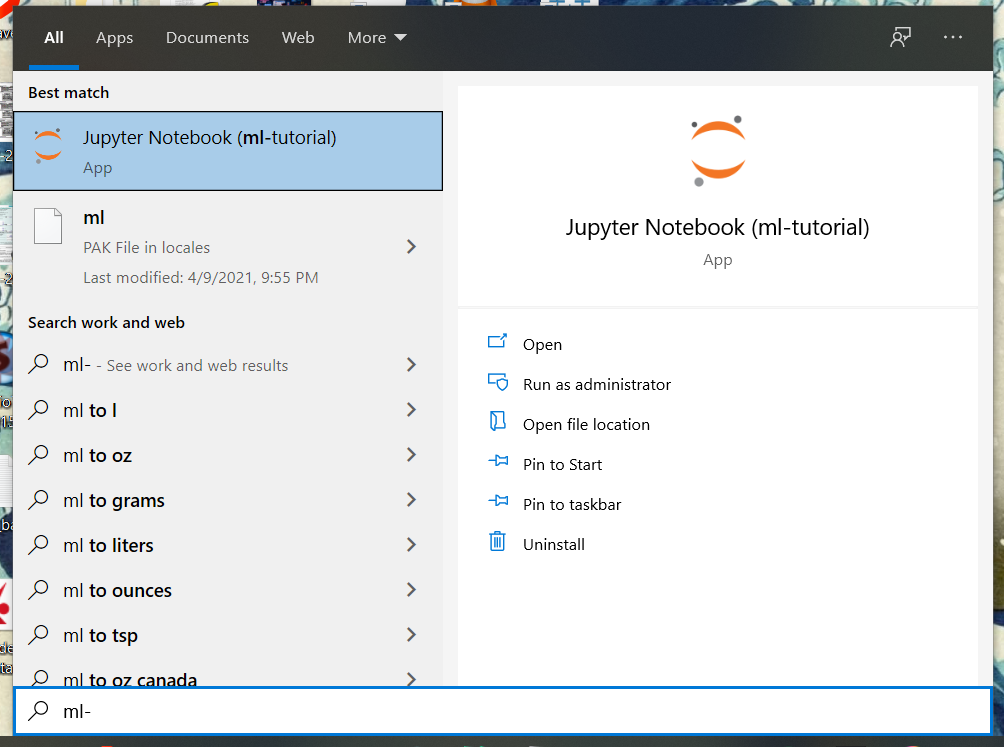
Clicking this application spins up a script that launches a server to host your python environment and a look at your directory and files. A little along these lines:
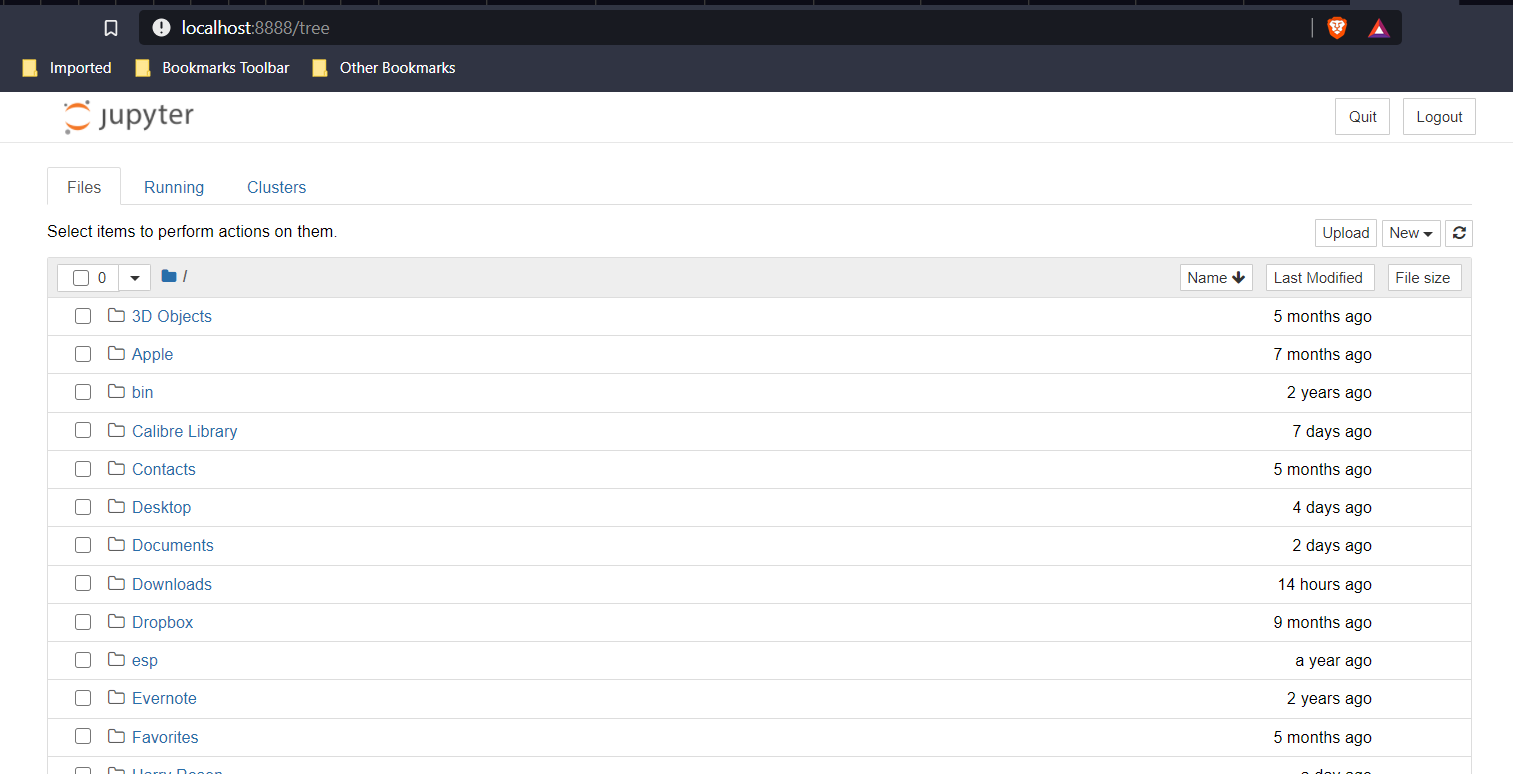
Here’s where you click on New, select Python 3 and a fresh notebook appears.
Making a machine learn
So you have a notebook open nothing else in the environment. Here’s where the magic happens! Because the solutions can be taken right out-of-the-box, you only need to come up with a problem. I’ll rely heavily on scikit’s example for a K-means cluster (algorithm for classifying groups). You should be able to directly copy pasta 🍝 the code there which is identical to the code below:
print(__doc__)
from sklearn.cluster import kmeans_plusplus
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# Generate sample data
n_samples = 4000
n_components = 4
X, y_true = make_blobs(n_samples=n_samples,
centers=n_components,
cluster_std=0.60,
random_state=0)
X = X[:, ::-1]
# Calculate seeds from kmeans++
centers_init, indices = kmeans_plusplus(X, n_clusters=4,
random_state=0)
# Plot init seeds along side sample data
plt.figure(1)
colors = ['#4EACC5', '#FF9C34', '#4E9A06', 'm']
for k, col in enumerate(colors):
cluster_data = y_true == k
plt.scatter(X[cluster_data, 0], X[cluster_data, 1],
c=col, marker='.', s=10)
plt.scatter(centers_init[:, 0], centers_init[:, 1], c='b', s=50)
plt.title("K-Means++ Initialization")
plt.xticks([])
plt.yticks([])
plt.show()
This code should run showing you the algorithm’s ability to classify clusters in a randomly generated dataset.
AI Takes Over
AI is the decision layer above machine learning that is based on the results. In this example above of a random dataset, imagine instead the information was everyone’s browsing history for a given day.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
The machine learning is the model that would put your browse history into a group whereas the AI would be the decision to target you with dog or cat advertising based on your cluster. Over time, your cluster may change or evolve and the machine learning algorithm will adjust accordingly based on the bird or turtle gifs you begin to check out.
Conclusion
There you have it. Your first start at a quick machine learning solution created locally. It’s not exactly clear how it’s immediately useful, but i’ll end on a quote that is relevant to how you might tihink about using it; “If I had an hour to solve a problem, I’d spend 55 minutes thinking about the problem and 5 minutes thinking about solutions.”